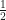This blog gives a very thorough introduction to general issues.
This blog explains why should we choose cross-entropy instead of error rate as loss function.
This blog offers a very comprehensive list of how can GAN be better trained.
softmax
regularization
Weight initialization
From Tensorflow tutorial:
To create this model, we’re going to need to create a lot of weights and biases. One should generally initialize weights with a small amount of noise for symmetry breaking, and to prevent 0 gradients. Since we’re using
To create this model, we’re going to need to create a lot of weights and biases. One should generally initialize weights with a small amount of noise for symmetry breaking, and to prevent 0 gradients. Since we’re using ReLU neurons, it is also good practice to initialize them with a slightly positive initial bias to avoid “dead neurons”.
How to choose a neural network’s hyper-parameters?
Moving average from Tensorflow tutorial:
When training a model, it is often beneficial to maintain moving averages of the trained parameters. Evaluations that use averaged parameters sometimes produce significantly better results than the final trained values.
batch normalization, for gradient vanishing
stride convolution replace pooling, for fast computation
This page gives a very good example on how to implement stride convolution.
drop out
max out
Autoencoder
An autoencoder has a lot of freedom and that usually means our AE can overfit the data because it has just too many ways to represent it. To constrain this we should use sparse autoencoders where a non-sparsity penalty is added to the cost function. In general when we talk about autoencoders we are really talking about sparse autoencoders.