Draw (Scale)
Spatial Transforming Network (affine transform)
Deformable network

Draw (Scale)
Spatial Transforming Network (affine transform)
Deformable network
PixelRNN/ PixelCNN
Each pixel is depended on other observed pixels. D

http://kawahara.ca/conditional-image-generation-with-pixelcnn-decoders-slides/
Gated PixelCNN
PixelRNN is accurate, but it is slow to train since RNN is hard to parallelize. PixelCNN is proposed to solve this problem. A mask is used to ensure convolution operation only uses previous pixels. To avoid “blind spot” problem, there are horizontal and vertical convolutions.

The authors believe another reason for the good performance of PixelRNN is that they have “multiplicative units” in the form of LSTM gates, which may be helpful to model more complex interactions. “Gated convolutional layers” were proposed in this way.
y = tanh(Wx)⊗sigma(Wx) , where ⊗ is element-wise production

When we stack these gated convolutional layers together, we’ll obtain Gated PixelCNN.

PixelCNN++
This paper made several modifications to Gated PixelCNN. One interesting change is the long range connections as shown in figure bellow.

Multiscale PixelCNN
This work aims at speeding up the computation of PixelCNN. By generating multiple pixels in parallel, this algorithm is able to reduce the complexity of original PixelCNN from linear to logarithm.
PixelVAE
VAE can generate smooth images with good global feature, however, it is not good at recover local features.
PixelCNN can extract local features pretty well, but not good at extract global features.

PixelGAN
The coolest idea of this is to decoupled categorical variable with continuous variable, which is kind of similar to InfoGAN. The difference is that here, categorical variables are learned by Adversarial Autoencoder and continuous variables are learned by PixelCNN

Laplacian Pyramid
Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks
Multiscale PixelCNN

ALI
CelebA 128×128

StackGAN


OctNet

Laplacian Pyramid
Hierarchical Surface Prediction for 3D Object Reconstruction
Tensorflow and VTK can’t tolerant Theano access GPU at the same time. Errors similar to bellow will appear.
F tensorflow/stream_executor/cuda/cuda_driver.cc:316] current context was not created by the StreamExecutor cuda_driver API: 0x40e0f10; a CUDA runtime call was likely performed without using a StreamExecutor context
The way that I used to get around is:
https://github.com/tensorflow/tensorflow/issues/916
ERROR: In /export/doutriaux1/build/build/ParaView/VTK/Rendering/OpenGL/vtkXOpenGLRenderWindow.cxx, line 382
vtkXOpenGLRenderWindow (0x2a1d710): Could not find a decent visual
ERROR: In /export/doutriaux1/build/build/ParaView/VTK/Rendering/OpenGL/vtkXOpenGLRenderWindow.cxx, line 601
vtkXOpenGLRenderWindow (0x2a1d710): GLX not found. Aborting.
command to add files
git commit -a
The *args and **kwargs is a common idiom to allow arbitrary number of arguments to functions as described in the section more on defining functions in the Python documentation.
Similar to dir() in matlab, walk() can return all file path in a folder.
For example, every image in the Frey face database is a two dimensional matrix, and all those pictures together can form a large three dimensional matrix. We will do 3D PCA on this matrix. This has the potential to preserve the spatial relation of the pixels in images.
Emphasize emphasize
Strong Strong
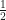
This blog gives a very thorough introduction to general issues.
From Tensorflow tutorial:
To create this model, we’re going to need to create a lot of weights and biases. One should generally initialize weights with a small amount of noise for symmetry breaking, and to prevent 0 gradients. Since we’re using
To create this model, we’re going to need to create a lot of weights and biases. One should generally initialize weights with a small amount of noise for symmetry breaking, and to prevent 0 gradients. Since we’re using ReLU neurons, it is also good practice to initialize them with a slightly positive initial bias to avoid “dead neurons”.
How to choose a neural network’s hyper-parameters?
Moving average from Tensorflow tutorial:
When training a model, it is often beneficial to maintain moving averages of the trained parameters. Evaluations that use averaged parameters sometimes produce significantly better results than the final trained values.
batch normalization, for gradient vanishing
stride convolution replace pooling, for fast computation
This page gives a very good example on how to implement stride convolution.
drop out
max out
An autoencoder has a lot of freedom and that usually means our AE can overfit the data because it has just too many ways to represent it. To constrain this we should use sparse autoencoders where a non-sparsity penalty is added to the cost function. In general when we talk about autoencoders we are really talking about sparse autoencoders.
Confusion matrix
Area Under Curve
and others

